
- 下载wine for Mac (链接: https://www.winehq.org
https://sourceforge.net/projects/wine/
2. wine 文件是tar.xz , 在linux 下Linux下tar.xz结尾的文件的解压方法?
在linux centos7.5 1804 gnome 安装好了wine, 但是没有试着打开exe,
https://sourceforge.net/projects/wine/
2. wine 文件是tar.xz , 在linux 下Linux下tar.xz结尾的文件的解压方法?
在linux centos7.5 1804 gnome 安装好了wine, 但是没有试着打开exe,
目的:在os 上安装好破解版,用于连接virtualbox 虚拟机,
参考来源:http://www.sdifen.com/securecrt812.html
一、已有资源:
1.电脑:Mac OS 10.13
2.下载了的软件版本: securecrt 8.1.2.dmg (破解版下载链接:https://sdifen.ctfile.com/fs/1855249-203417914)
二、安装过程中遇到的问题:
———– 在Mac 或者已经安装了linux的虚拟机上执行.exe, 特别是安装wine 就很耗时间,———–直接淘宝就好,不折腾
【第三书】
四月二十九日
絮:
下午四点多时有一通电话,昨晚信写得太晚,人还在床上,今天的一天还没展开,一瞬间觉得可能是你打来要关心免免的葬礼,但来不及爬起来电话铃声就停了。我放弃了可能是你打来的念头。在这段努力要将我甩开、视我如洪水猛兽的时期,你大约不可能勉强榨出几滴真心关爱来罢。
絮,你这个月对我的所作所为是错的,你对待我的态度是错的;我必须对你这样说。站在一个人对人的立场上来讲,尽管我较你年长老成,尽管你再怎麽年轻不懂事,但每个人一生都要对自己做过的事,以及对他人犯过的错负责,每个人在内心里都逃不掉那份责任的,我也是,我也在为我对他人所犯的罪做偿还。
我认为人与人之间是有情有义的,至於情义的内容或范围是视两人间的默契或誓约而定的。人的内在、生命、人格的「一致性」愈高,就愈能真实地、诚信地活在这样的默契里;人间的这种「一致性」太低,就会不断地去对他人犯错,内在产生混乱,或是不得不完全封闲自己的精神。这种「一致性」就是Gabriel Marcel所探讨的fidelite(忠诚)的问题核心。这一个月,我又更用心地去研Marcel,我发现我的生命已发展到可以更加懂得他的整体精神,也可以和他的关怀范畴整个叠合了。我很高兴,像是找到知交一般,想要学小提琴有一部分也是被他所感动,想要追随他。
———————————————————————————————————-
她写的只是自白吧,也只能自白于己
一、背景:
小白在mac os 上安装virtualbox 用与虚拟安装linux centos 环境熟悉linux 命令。
二、过程:打开Virtualbox manager 界面,安装新虚拟机的过程:
new —-name:test—-select linux —redhat
—分配内存1g(本机的1/4),
—-创建虚拟盘—格式—vdi disk image 光盘映像—-硬盘分配模式:动态分配适合节省空间,固定分配速度更快,因为磁盘空间不像动态分配那样分散,而是连续的空间,所以速度会快
——配置此虚拟机的network,问题如下
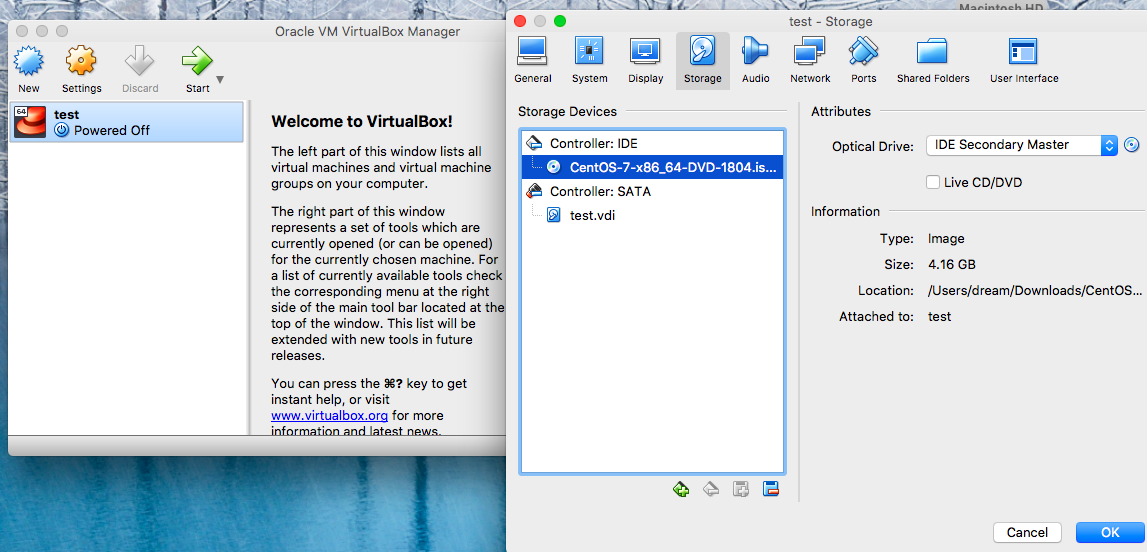
——-storage 界面挂载光盘,控制器sata =虚拟硬盘, ide controller=虚拟光驱,把下载好的centos .iso 挂载到此——–启动start 虚拟机—-开始进入centos 安装界面—-skip disk check—-语言设置—-存储设备—选择分配好的虚拟硬盘—选择存放位置—setting host name—-setting network—-wired: 自动连接,—-ipv4 setting:1.method:自动获取(DHCP)如果家里路由是自动获取可以这样选,但是如果是做web server 等服务器还是不要这种动态获取,最好选静态获取ip ,所以此处我们选“手工设置”:填写ip adress, 掩码24不用改,gateway:网关是指家里路由器的地址,dns 服务,比如电信的网址,——–时区—–超级用户设置——安装哪种base server,参考link: —-选择basic server—-
安装过程中的问题:
VB –setting — network 网络连接的6种不同选择:
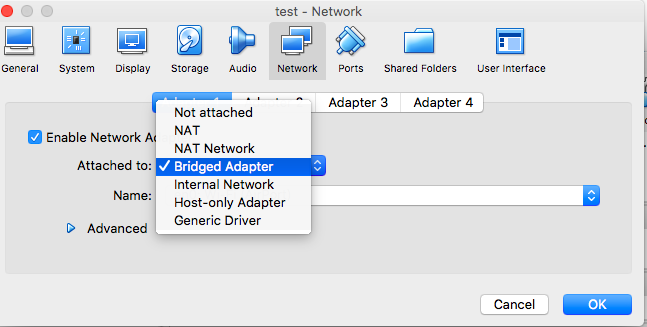
VirtualBox can provide DHCP services for this network mode.
A NAT Network must be created before a guest interface can be assigned to it, via File > Preferences > Network > NAT Networks.
Note: Even from the host system, the services on the guest system cannot be accessed. If access should be possible, an additional interface can be configured using Host-only networking.
In Vagrant terminology, this is a public_network. In Docker, this is called Host mode.
VirtualBox can not provide DHCP services for this network mode.
Multiple host-only networks (and host loopback interfaces) can be configured.
VirtualBox can provide DHCP services with this network mode.
A Host-only Network must be created before a guest interface can be assigned to it, via File > Preferences > Network > Host-only Networks.
参考资料及其引用源:
背景:
Mac OS 10.13
virtualbox.dmg
安装过程:
安装过程中的问题:
一、目标:使virtualbox 下的各个linux虚拟机也能上网。
二、背景:
三、手机热点下虚拟机选择桥接网卡(bridge adapter)时的问题探索及解决过程:
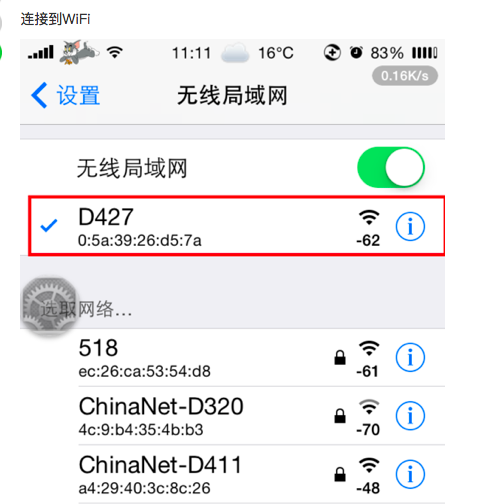
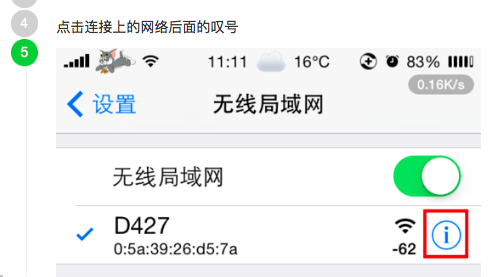
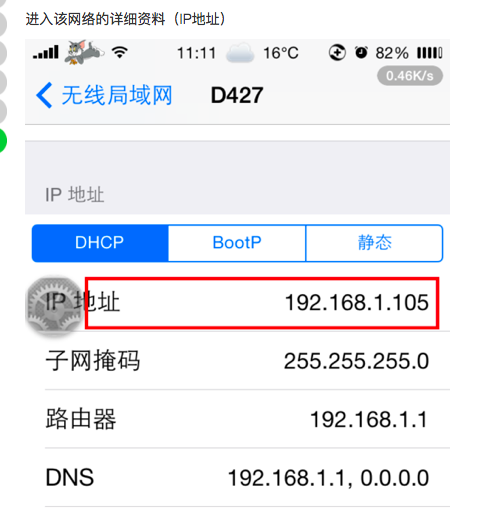
参考资料和引用资料:

转载:https://www.imooc.com/qadetail/262985
2018-06-13源自: Linux达人养成计划 I… 2-8166 浏览1 回答
转载:
转载:笔记本链接手机热点怎么配置虚拟机也用此热点https://zhidao.baidu.com/question/2014135630525657428.html
1.首先建立个临时网络。网络和共享中心-建立新的连接-建立无线临时网络计算机到计算机-输入网络名和密码-确定。
2.在更改设配器设置中右键无线网络属性,把tcpipv4的ip和dns设置成自动获取。
3.右键宽带连接属性,选择共享选项卡 勾选“允许其他计算机通过此计算机连接internet”之后在下拉菜单中选择无线网络1共享此连接。
4.设置后的本本打开无线 连接你刚刚设置你临时网络,手机搜索该临时网络,并输入密码即可实现wifi上网。
我家里就是这么设置的,一个本本通过猫上网,另一个通过此本本建立的临时网络上网,手机也是一个道理。ipad也能通过此方法
最近虾米给我的推送让我有这样的感受:有时是虾米在听我,有时是我在听虾米,我听她推荐的节奏,她听我想给出的节奏。如果让5年前的自己听现在的post rock 我可能一下子无法接受,但有些节奏一旦形成便让自己无法忍受非期待的节奏。比如等一趟公交,一个个内容复制和录入,手眼并动的机械活越来越让人麻木,明明可以用工具,为什么要手动?这是过去2年受到的熏陶之一,深入骨髓了?
如果没有结果导向,所有的节奏要么变慢,要么杂乱,这不是试错,这是浪费时间。
我今天看到glow curve 那猩红色专辑封面,又想起了河城,想起那个流放、隐没,最后坠河的歌手,死在旋转公寓可能是最适合她的BGM。
有时觉得你什么都想要,过于自我苛求,才一无所有;
有时觉得你什么都不需要,读不出你一点点欲望,才一无所有,太虚伪了!
这几天一边是技术类讲整个建模流程,一边是社会科学或者经济行为学心理学类,有时候看着看着会觉得不同书的作者不时的偷换概念或者说稍以转下视角讲着类似的故事不同的情节而已。
这种现象在社科行为经济学里尤为显著,可能西方人喜欢表达造就了同一个研究出现了不同称谓的术语和定义吧,比如被反复提到的一些关键词:锚定,第一印象,比较,陪衬,社会规范,市场规范 , 即时满足与延后满足,对所有物的自我预估等。而在建模那一块,最明显的就是去年那本统计学上走马观花的留在我脑海里的概念在整个建模流程里全部蜂拥而出,尽管很多概念我从来都没理解透过,甚至连公式的推导都看不明白,但统计和数据建模的贯通可以帮我理清不少大方向上的思路,比如数据特征,属性之类的东西,描述性与预测性的区分等等,这些在统计学里确实是最基本的概念。
到这里我终于可以省点时间剔除重复性的东西并强化不懂的部分了。不能说很不容易,只能说要再接再励到另外一个层上,等再往下看积累又多了一层。
 早在2009年开始听Lady&Bird,那个寒假我没有回家,在一家服装店兼职导购,清闲的时候只有我一个人看店,于是我多了很多时间去玩一些平常上课不怎么玩的东西,简称业余爱好。
早在2009年开始听Lady&Bird,那个寒假我没有回家,在一家服装店兼职导购,清闲的时候只有我一个人看店,于是我多了很多时间去玩一些平常上课不怎么玩的东西,简称业余爱好。
人在自己当下的年龄认同区间内一般关注同年龄段相关事物较多,那个时候的我也是如此:比如我帮芳姐每天去“偷菜”,隔几天去校内(现在的人人网,中国版FB)看看同学的动态, 跟风在新浪博客上写小故事或者无病呻吟,跟风开通所谓的新浪围脖。宿舍某女男友是个会写小说的社长在我们的时代就是件很fashion 的事情,因为那个时候晋江正是红火之时,说起来那个社长似乎还有跟某网签约。
出于对新浪博客的狂热,我几乎每天都要花2-3小时看自己的博客和他人的博客,博客空间里有个添加Music list 的功能,迷上light music 的我四处百度无意中便加了一首Keren ann 的歌曲,suicide is painless ,接着Lady&Bird 的专辑歌曲几乎霸占了整个list的滚动条。接下来的2年里我的MP3,MP4里塞满了Lady and bird 的声音。后来到了GZ,也就是所谓的很多年后,我第一次见到了Bardi, 虽然不能看到Lady 和Bird 同台演唱很是遗憾,但Bang Gang 还在Keren还在 就会让我觉得Lady 和 bird 以后还会合作的。

而今天是我第一次见Keren, 不知道是不是我不太喜欢大剧院和音乐厅这样局促安静庄严的环境还是我习惯了livehouse里自在的吵闹喧嚣,整场听下来我有些许失望和不尽兴,但如果还有下一次我依旧会去听。
允许我怀念下这个组合,BGM-Don’t feel ashamed
AI 前线导读:根据美国财富杂志的报道, Amazon 的销售额高速增长,得益于它将系统整合进用户购买, 从产品发现到付款的整个流程。根据华尔街分析师的估计, Amazon 的在线推荐系统的购买转化率高达 60%。 那么 Amazon 推荐系统的成功秘诀在哪儿呢,让我们为您揭开其神秘面纱。
声明 | 本文整理自 AI 前线 2018 年 3 月 1 日直播分享,未经许可不得转载!
大家好!很高兴今天有机会跟大家一起分享个性化的智能推荐系统。
我先自我介绍一下,我叫袁源,2011 年获得博士学位,曾经在亚马逊工作有两年半的时间。在这些工作中,我有一些经验可以给大家分享,所以趁今天这个机会跟大家聊一聊。
时间有限,我可能会讲的比较抽象,如果大家希望了解具体的内容,可以扫我们的二维码,来我们贪心科技的网络课程,在里面我会把今天讲的每一个算法用最详细的语言和最清晰的、最有条理的方式给大家讲解,并且每一种算法我都会用 Python 写好代码分享给大家,所以说大家不但能够从理论上学到一个算法、能够理解它,并且能够看到这个算法怎么实现的。我在实现算法的时候,会尽量不用任何第三方的库,我尽量不用那些已经打包好的,可能很多现成的人工智能的库是 C++ 写的,并且为了效率可能用上了 GPU。我会用最纯粹的 Python 写,这样的话,大家就可以看到很详细的每一个步骤是怎么实现的。
如果大家有兴趣,知道详细内容的可以继续扫我们二维码,到我们贪心科技的网站上了解更多细节。
weixin.qq.com/r/eCqPl5XE6… (二维码自动识别)
今天和我一起和大家分享的还有我们的 CEO,李文哲,文哲现在你可以给大家打个招呼吗?
李文哲:大家好,我叫李文哲,我目前是贪心科技的 CEO 也是创始人。我之前也是在美国读人工智能博士的,我之前是在 USC。在国内多家企业也做过首席科学家,所以我对整个的 AI 领域还是比较熟悉的。
我创建这样的一家公司是希望把这种 AI 的技术还有 AI 的知识普及起来,让国内的很多人可以去学习,然后在实战中能够用起来,今天我们也很高兴邀请到了 Jerry 老师来分享推荐系统这样的一个课题,希望大家在今天的课程当中学到一些知识。如果有任何问题,我们可以一起讨论,也可以给我提问,到课程结束之后,我们一起在论坛里面再互动一下。接下来我们就把时间给 Jerry 老师。
袁源:那我们现在正式开始我们今天的分享。
我今天的主要内容如下:
首先我给大家介绍一下推荐系统的概述,它代表什么,有哪些具体的推荐系统实现我们可以借鉴;
第二是我给大家推荐一下常用的推荐算法,如果你自己正要做一个系统的话,你可以从这些最常用的算法开始尝试;
然后我想强调一下大家可能不太重视的一点,就是如何评价一个推荐系统?只有你建立一个比较好的评价标准,你才有办法不断的改进你的算法,让你的系统运行的越来越好;
最后,我会介绍一下现在已经存在的一些推荐系统它们一般会怎么来架构的,以及如何从软件系统上来描述它。
推荐系统概述
首先什么是推荐系统?
我们要先定义一下,我们今天到底讲什么。
推荐系统其实就是一种信息处理的系统,用来预测一个用户对某个东西是不是很喜欢,如果喜欢的话,喜欢的程度是什么样的,是非常喜欢,还是一般般喜欢,还是一点都不喜欢。推荐系统用的领域肯定很多,我举一些例子:现在的今日头条给用户推荐个性化的新闻;优酷土豆 YouTube 给用户推荐视频;虾米音乐给用户推荐喜欢的音乐,当然还有淘宝、京东商城推荐图书、食品、衣服还有其他各种商品。除此之外在社交网络里面 Twitter、Facebook,还有像新浪微博,都会给用户推荐朋友。
当然,推荐的方式也是用推荐系统来实现的。现在金融很火,如果你在做金融类的产品,肯定希望做 P2P 金融给你的客户推荐股票、基金理财、基金证券和理财产品。当然单身狗们不要忘了在婚恋市场里面的各种相亲网站里面,也会给单身的朋友推荐合适的另一半,同样是用的推荐系统。
所以说我们可以看到推荐系统现在已经成为很多网站、手机 APP 不可获缺的一部分。这些 APP 和网站依靠推荐系统来提高销量,吸引用户注意力,提高用户活跃度和吸引新的用户。
因为我曾经在亚马逊工作,我们来看一个具体的一个公司它是怎么使用推荐系统的。
我现在显示的是 Google felines 里亚马逊的股价,可以看到,它最近简直像发射火箭一样,股价一直上涨的非常厉害。从 2015 年大概 300 美元一股,现在涨到了 1500 美元一股。
那它这么成功它靠的是什么?我们看看美国著名的《财富》杂志是怎么价值它的:它说亚马逊的成功取决于它把它的推荐系统放到了从产品发现,到产品购买的整个过程。
财富杂志还提到说,亚马逊的推荐系统在进行推荐以后,用户购买率、转化率会达到 60% 的程度。
那我们来具体看一下亚马逊都使用了哪些推荐呢?
如果你登录到亚马逊网站上,第一个你会看到,它会按照不同的产品类别进行推荐,比如说左上角,它推荐给当前登录的 taomas 这个用户,给他推荐健身器材,左下角又推荐咖啡和茶,还有其他的图书,这是第一个:按照类别给每个人推荐。
第二个是经常购买的商品。
假设一个用户现在购买了左边的这一个训练机构的这个健身棒,它就会推荐你买右边的这个橘黄色的这个健身的按摩球,为什么呢?这两个东西根据它们的历史显示经常被人一起购买,这也是个经典的案例,大家可能会知道 MBA 里面的一个经典案例:研究人员发现,超市应该把婴儿尿布和啤酒放在相邻处,因为很多父亲去买婴儿尿布,同时看到旁边有啤酒,就会一起购买,这也是采用样的策略。
第三,亚马逊推荐的方式是按照你最近的历史推荐。
你最近看了什么?我最近看了健身用的健身棒,所以推荐的一堆用来健身相关的物品。
第四是什么?不是推荐你曾经没看过的,而是告诉你今天看了什么、前几天看了什么、某月某日看了什么,把你曾经看过,但是并没有下单的东西再给你看一遍,也许你就有下单的冲动了。
第五是什么呢?也是按照你的浏览历史给你推荐,不是按照你现在的浏览历史,比如我最近看的是健身器材,但是给我推荐的第二个商品是沙丁鱼,他是按照我曾经久远的历史来给我推荐的。
还有第六种推荐,就是按照其他跟你购物习惯相同的用户推荐,比如他和我买了同样商品,他接下来又买了什么,根据其他跟我买相同商品的用户购买的物品的推荐。
第七是,系统知道我的购买历史,知道我曾经买了一个 kindle,然后告诉我说,现在 kindle 出了新版本,那我会不会想要购买,这是根据用户的购买历史推荐同一个商品新版本。
还有第八,它根据我的购买历史推荐周边产品。系统知道我买了 kindle,他就推荐我说你要不要其他周边产品,比如保护套。
第九,就跟我个人购买历史和我个人的浏览历史无关的,而是根据在亚马逊网站上卖的比较好的那些商品进行推荐。
除了登陆网站,系统会给你推荐之外,它还会主动进行推荐。在美国大家用邮件用的比较多,都是用邮件来登陆的,所以说亚马逊知道美国用户的邮件,就会给用户发邮件进行推荐。
比如说这个例子:我最近看了一下佳能的数码照相机,它就会给我发邮件,给我推荐佳能最近卖的比较好的照相机给我。
如果我无动于衷,它又会有推荐:佳能的你可能不感兴趣,推荐柯达的数码相机给你看你会不会感兴趣?这就是跟我曾经浏览相似的东西,但是呢,只是局限于柯达这个品牌。
如果我还无动于衷,他还会给我发邮件说,你看佳能的相机,这里有一个便宜的一个套件,包括相机的壳子、包括记忆卡,一起买会比较便宜,你会不会感兴趣?推荐系统会按照你曾经浏览的物品推荐周边产品,做一套件给用户购买。
最后,如果用户还无动于衷,它还会给你推荐,比如直接告诉你,卖得最好的数码相机是什么。除了我曾经自己看的佳能,还有索尼的,这就是它给我推荐的东西。
我每种推荐的算法标了一个数字,到这里一共是 13 种,也就是说:简简单单的一个购物网站,仅对每件商品的,就用了 13 种不同的推荐策略。
我们高屋建瓴来看一下,各种推荐到底背后的算法是什么呢?
如果我们把推荐系统来分类的话,其实我们每个人都接触到推荐系统,这是一个很原始的技术。
早期的门户网站,比如说新浪、雅虎,还有人民日报也是有推荐系统的,只不过里面的内容是网站编辑,或者是报社的编辑帮读者手工选择的,它也是一种推荐,只不过是手工生成的推荐。
第二类推荐,是一些简单的聚合系统。比如说你去 KTV,点唱面板上就会有 KTV 的最近点唱的排行榜,如果你去书店就有畅销书排行榜,去买电影票,猫眼电影之类的系统也会告诉你热卖电影是什么;包括豆瓣里面会有电影票房排行榜。
还有按照物品的时间顺序,按照时间性质给用户推荐,比如说新上架的物品优先推荐。
这些推荐系统只是基于最简单的统计来进行推荐,他们虽然说看起来方式很简单,但很多时候很有效。
最后一个就是我们关注的重点,就是真正个性化的千人千面的推荐系统。
无论是第一种,还是第二种,你会看出来不论是人工生成的推荐系统,还是简单的聚合,它 都不是针对个人的。每个人打开人民日报看到的是一样的内容,每个人去 KTV 里面点歌看到的排行榜是一样的。那我们现在最关心的就是千人千面的推荐系统,比如说每个人打开 Amazon 主页,每个人打开 Netflix 他会看到这些商品,或者电影的推荐是不一样的,那这就是我们今天想要关注的重点。
如果我们从数学上来抽象一个推荐系统,应该从理论上来看是个什么样的?有什么样的要素、要解决什么样的问题呢?
首先我们用 U 代表所有用户的集合,我们有一堆的用户,然后我们用 S 代表所有物品的集合,比如说我有一堆用户,我有一堆东西,这些东西可能是电影,可能是音乐,可能是人,可能是其他的物品。我的推荐系统模型也就是说:U×S,推荐出来 R,这个乘积在这里表示笛卡尔积。意思就是说:每个用户和每个物品我给它一个 R,这个 R 的值就是推荐值,就是说每一个用户对一个物品他的喜爱程度是多少,很多的网站会有,让你打分就是一到五颗星星这种方式来表达,也有像 Facebook 用点赞的方式,或者是鄙视这种方式来表达,这就是 R 代表的值,推荐系统说到底也就是一堆用户对于一堆物品的喜欢的程度的值。
举一个大家都能明白的实例:假设我有小明、小李,韩美美和小静这四个人。有四个电影作为我的物品:《大话西游》、《夏洛特烦恼》、《黄飞鸿》、《笑傲江湖》。那我能掌握的数据、能够收集到的做推荐系统的数据是哪些呢?
首先是推荐值里面记录了每一行是每个用户对于各个物品的喜好程度。比如:小李对于《夏洛特烦恼》喜欢程度是 2,对《黄飞鸿》喜好程度是 5。
在这个推荐矩阵里,你会看到有的人数值是已知的,有的是未知的,比如说小明对《大话西游》他的喜好程度是什么呢?我们不知道,这就是我们想要的,同样也是推荐系统的一个关键问题:我们怎么从我们这些已知的这些推荐值推导出这些未知的值? 比如小明对《大话西游》的喜好程度,除此之外我们还能获取哪些数据呢?当然我们获取用户的数据,每个用户有性别、年龄和其他的属性,这些是我们可以获得的;还有物品的属性,比如我们能轻易的获取这个电影的类别,是武侠还是文艺片,还是喜剧,这也是后续另外一些物品的属性。
有这三个矩阵,这些值就是我们可以利用的值,然后我们要解决的问题就是利用这些获取的数据推导那些位置的值,比如小明对《大话西游》的喜好程度。
我强调一下推荐系统要解决的关键问题:
第一是 收集数据。推荐系统本质上说,当然是一种人工智能系统,人工智能系统需要 Training,需要训练,它当然需要训练数据了,所以说收集数据非常重要。我觉得有一点要注意:收集数据不是一蹴而就的,需要经常更新的,数据有时效性的。比如说一个人对一个东西的喜好程度是随着时间变化而变化的,每一个人童年喜欢的书籍电影在成年后可能就不喜欢了;可能你去年喜欢的东西和今年就不一样,也许你的兴趣爱好变了。还有比如说一个用户他现在小孩出生了,他可能关注更多的婴儿物品,比如说尿不湿,所以说收集数据很重要,而且收集数据是经常需要更新的。
第二,推荐系统要解决的关键问题当然就是如何预测那些未知的数据;
第三个就是 怎么建立评价系统。只有建立一个评价系统,才能知道现在我的推荐系统到底好不好,如果不好,我们调整,怎么调整算是好?
收集数据
收集数据有一种方式,是显示收集,就是直接让用户打分,或者是点赞,或者让用户留言评价。这有一个很大的问题,就是很多用户不愿意,或者懒得点赞、写评论,或者是打分。比如说我自己,比如我在 YouTube 上看了很多视频,我从来没有给他们点过赞,或者是写过评价说:“非常不错”或者是“很讨厌”,我从来不评价,我相信很多人会这样子。
在没有办法收集数据的情况下,有没有其他方式来收集呢?这就是越来越多的 隐性收集 数据,那怎么隐性收集呢?比如说一个视频网站,如果一个用户看了一部电影,过了一段时间发现他又在看那部电影,表示他很喜欢这个电影;如果他在观影时一直快进,或者中途就跳开了,那就说明他不喜欢,这就是隐性收集的一个策略。
购物网站就更简单,如果一个用户买了某个东西,当然就表示他喜欢某个东西,如果他退货了,肯定就表示不喜欢。隐性收集现在越来越重要,而且隐形收集的数据远远高于显性收集的数据。
如何预测
得到了数据之后,我们如何来预测呢?它关键的挑战有哪些?
我们得到的推荐值矩阵就是一个用户到底喜欢什么东西,但实际上,得到的数据基本上是非常稀疏的,意思就是说大多数用户对大的物品喜不喜欢我是不知道的。我们只知道,每个用户可能对少量物品的喜好程度,或者是某一个物品只有少量的用户喜欢,所以他表达出喜好。
还有就是冷启动物体,这是什么?假设我现在有一个新的物品,比如说 iPhone11 要放在我的购物网站上,没有任何用户为他打高分,因为它刚出来,没有人用过,自然没有反馈了,你怎么推荐它?你怎么知道人家是喜欢 iPhone11,还是喜欢华为 P11?
还有就是新的用户。如果有个新的用户上来,他没有任何的交互行为,你根本不可能知道他到底喜欢或者不喜欢什么,这就是一个很大的挑战。
那常用的推荐方法有哪些呢?如果你现在要负责公司,做一个推荐系统,我建议你在我先要介绍这个列表里逐一试过来,再去使用更 Fashion,更先进的方法。
我会逐一把它们做些简单的介绍。
第一是 基于内容 的,这里有一个图来简单介绍,表达它的意思。
假设一个人他喜欢这种酸酸的啤酒,就让系统找跟这种啤酒所有相似的口味的其他啤酒,如果找到另外一个,当然就可以推荐给他。
基于内容推荐看起来是最简单最容易实现的,效果反而也是还不错的,但是它的问题在于很多情况:很难获取一个物品的属性。如果基于内容,基于产品的属性找到两个相似的产品做推荐,怎么判断两个产品相似呢?不是一件容易的事情。
比如给用户推荐两篇新闻,怎么判断两个新闻相类似呢,需要用到自然语言理解,系统需要知道这篇新闻里面包含了哪些人物、哪些事件、哪些地点、哪些时间,这篇新闻里边是不是有国家元首,如果这两篇没有国家元首,至少某种程度上是相似的;或者这两篇文章是不是都包含了比如北京的事情,是不是都包含了同样的主题,它们是都在谈政治、都在谈军事,或者都在谈经济呢。基于内容这种推荐方法,最关键的问题是怎么获取这个物品的属性,对于文字,可能会用到自然语言处理;对于图像,可能需要用到深度学习的图像识别技术,知道这个图像图片里面到底包含了哪些物体是人、是狗、还是猫,如果是猫的话,这两个方式相似的,是不是橘黄色猫?这就是基于内容的方法。
第二种方法是 协同过滤 的方法。
我给大家举个最简单的例子,但是你马上就能理解协同过滤。
假设我有三个用户和四个物品,分别是橘子、草莓、苹果和香蕉。我知道第三个用户他购买苹果,接下来,我问你:在其他的三个他没有购买的物品,橘子,草莓和香蕉里面,第三个用户可能会最喜欢的哪个?
基于协同过滤的考虑方式是这样子:我们希望给第三个用户推荐的物品应该是跟他已经购买的苹果相似的物品,那什么物品可以和苹果相似呢?我们可以这样思考,什么物品在用户购买苹果之后,被同时购买的次数是最多的?
我们先看香蕉,香蕉有没有跟苹果同时购买?有,第一个用户,他同时购买了橘子、苹果和香蕉,香蕉我们算它得了一分,因为跟苹果同时购买了,所以加一分;那我们再看草莓,草莓没有任何人买草莓的同时也买过苹果,草莓得分是 0 分;那么再看橘子,第一个用户,他同时购买了苹果,和橘子,第二人也同时购买了苹果和橘子,所以说橘子得两分,它跟苹果的相似度是 2。这样我们就发现苹果跟橘子相似度是 2,苹果和草莓相似度是 0,苹果跟香蕉相似度是 1,得出结论:橘子跟苹果最相似,我们就给第三个用户推荐橘子,这就是协同过滤的精髓。
接下来我们再介绍 矩阵分解 方式。
举个例子,这里面 ABCD 四个用户,我们有 WXYZ,四个产品,我们知道用户对产品的喜好程度,比如说 A 对 X 的喜好程度 4.5,就给我们这样一个打分的矩阵,我们怎么来预测比如说 A 对对 W 它的喜好程度是多少呢?
矩阵分解的最好方式是这样子的:我希望找到另外两个矩阵,分别叫做 用户矩阵和物品矩阵,用户矩阵行的个数是等于我这个打分矩阵里面用户的个数,物品矩阵里面列的个数是等于物品的总数;至于用户矩阵的列,它一定要等于这个物品的矩阵的行数,那它的列数和行数具体等于什么值呢,是一个参数里你可以预设的,可以是 2,可以是 3,可以是 10,可以是 100。
这两个矩阵用户矩阵和物品矩阵应该有怎样的属性?我们希望他们的属性是这样子:当这两个矩阵相乘,他们乘的积肯定是一个矩阵,和我的打分矩阵是同样的行,同样的列;我希望他们两个乘积里面对应的值,它跟我的这个打分矩阵,应该同样行,同样列,那么就对应的值。
比如说第一行第二个值,我希望它的值是接近于 4.5 的,在 AX 位置接近 4.5、在 AY 位置接近 2.0、在 BW 这个位置接近 4.0,也就是说我希望这两个矩阵乘积的一个最终的矩阵,跟我打分矩阵里面已知的值是相似的。
如果可以做到这一点,那乘积的矩阵,它在这里是肯定是会对应值的,我认为这两个矩阵乘积以后对应的值就是我的预测的值,这就是矩阵分解的基本思想。
你马上可以发现矩阵分解它有一个问题:它只利用了用户对物品的打分的值,其实我们是知道用户的属性,比如说用户是男是女,是老是少,我们也知道物品的一些属性,比如说这个物品,如果是电影的话,我们知道它导演是谁,演员主演有哪些,他的风格是什么,但是我们没有办法在矩阵分解里面提供一些信息,因为数据没有办法提供,我们就没有办法利用它们来提高我们的系统。
所以就有人提出另外一种算法,叫因子分解机。
它的思路是:把用户对物品的喜好变成我下面定义的这样一个公式形式。它的意思是什么呢?
比如我这里有三个用户:汤姆、杰克和艾丽斯,我们有电影、图书和音乐,有他们互相之间的喜好程度,我把这个用户作为读者编码,每一行只有一个,人数为 1,1 就表示代表汤姆,然后另一行这一个 1 是代表杰克;然后是物品进行读者编码,每一行也是只有一个物品为 1,再把用户的属性,比如说年龄、性别放在这里,再把物品的属性放在这里;然后每一行,这些 X 数据分别代表是哪个用户,是哪个物品,以及这个用户的年龄是什么、性别是什么,这个物品的属性分别是什么;这个用户对于这个物品它的喜好程度是什么,这就是 Y 的值。也就是说,我们希望这些 X 的值通过下面这样一个公式的计算产生一个 Y 的值。
有一点跟矩阵分解很不一样的是:X 之间是有乘积的,是有相关性的。比如:汤姆的 X 值要跟汤姆的年龄、性别相乘;汤姆的值也要跟这个物品的属性相乘,性别或者年龄也要跟物品相乘,再互相交叉相乘,才能得到我们的变量。
这里面已知的值是 Y、X,未知的是 W,V 的值。我们只要通过计算知道 W 和 V 的值,就能对未知的那些 Y 做计算,因为 X 是已知的,这就是因子分解机的工作原理。
跟前面相比,这种方法就是同时利用对物品的喜好,也同时利用了物品的属性和用户的属性。
当然我们现在绝对不能忽略的一件事情就是深度学习的推荐系统。
我能想到的最简单的,用深度学习做推荐模型就是这样子的:输入式用户 ID,比如有一百个用户,分别对用户编码从 0 到 99;如果有一千个物品,就把物品编码从 0 到 999,作为深度学习网络的输入,然后加一个嵌入层,再把嵌入层输出的两个向量连接在一起,加入一个全连接层、加正则化,再加一个全连接层、再加正则化,再加两个全连接层,然后用 softmax 作为预测。
它预测的值分别是输出 000,或者假设想要的评分是从 0 到 5 打分,输出就是五个元素,分别是值为 0 和 1 的数。如果我预测它的打分是 1 分的话,那就是第一个元素为 1,其他元素为 0,如果我预测打分数目,那就是第五个元素为 1 其他元素为 0。
这就是一个最简单的深度学习模型,它唯一的数据就是输入就是用户 ID、物品 ID 和这个用户对这个物品打分的值,然后虚拟网络最后就会告诉你,如果你把一个新的用户 ID 和一个没有打过分的物品 ID 告诉它,它会预测一个打分的值。
讲一个实际使用的例子,这个稍微复杂一点,但是跟前面我介绍的大同小异。
这是 Google Play,相当于苹果的 APP Store,用来下载 APP 的,可能中国用的比较少。它用了这样一个深度学习的方式来做推荐:输入分别是用户的性别、年龄、用户一共装了多少个 APP、跟这个系统之间的交互是什么样子的,这些直接送到它的嵌入层里;然后是用户的设备,三星、华为、或者其他设备;以及用户安装了哪些 APP,和用户的对 APP 的打分情况是什么,这些都加入一个额外的一个嵌入层,跟前面的这些属性直接连在一起,加了三层的深度学习网络,之后直接把用户安装了 APP,和用户对已经安装的 APP 的打分两两相乘的积,作为它最后的输入。训练这样一个结构的神经网络,用在 Google Play 的 APP 推荐里面。
还有一种推荐的算法,是因为大家已经花了很多工夫来研究搜索引擎,搜索引擎本质上就是一个推荐系统。
比如输入“黄晓明”这个词到搜索引擎里面,不管百度还是 Google,会反馈很多的页面,第一个页面就是推荐系统认为,你会最喜欢的一篇关于黄晓明的文章或者网页,第二个页面是系统认为用户次喜欢的文章。
本质上来说,这种推荐就是:把一堆物品给某一个用户呈现的时候排序的过程,用户具体喜欢的物品不重要,重要的是用户比较而言更喜欢的物品。
如果收集了用户数据和用户打分的数据,就可以用传统的搜索引擎方式,去为每一个物品打分,然后进行排序,这是很传统但是很有用的一种方式。
还有一种方式,不用任何数据支持都能想到的一种,就是 探索与利用。听起来很 fancy,但其实原理很简单,这里举个例子:假设有 5 个用户,他们是一类的,就是很相似的用户,随机把用户 1 和用户 2 抽取出来,作为小白鼠做实验,给他们推荐两部电影,看看他们对电影的反应是怎么样的。
给第一个用户推荐一部,给第二个用户推荐另外一个部影,我们发现第一个用户没有点击电影,没有看电影,但第二个用户看了,就表示说这个电影更适合第二个用户这类群体的口味。那我就知道了,原来给第二个用户推荐的这部电影好,于是就可以给其他用户推荐被第二个用户点击过的电影。
为什么呢?很简单,因为这五个用户是相似的,我已经拿用户一和用户二作为小白鼠实验了,实验反映这个电影好,那我就应该给这些其他的用户推荐这个电影了。
但是还要注意一点:你也看到我们也给用户推荐了一部没有被用户一一点击的电影,为什么?如果我们只给所有的用户推荐,不用户点击的电影,万一用户一直点错了,他其实也是喜欢那个电影但他没点,或者他现在正忙,有什么原因看不了呢?那不就丢掉了这个好电影被用户看到的机会吗?我们还是要把它显示给某些用户看到,但是只能在显示的时候,显示的选择它的概率低一点,因为它明显被用户喜欢过。
最后不得不提就是 集成学习 的方法。
我们有很多不同的推荐算法,如果我把这些推荐算法全部加起来,合在一起,对用户会不会更好呢?现实的反映是会更好。
怎么来把这些不同的算法输出合在一起呢?第一个方式就是投票。假设有三个推荐系统,其中两个认为某一个用户对物品的喜欢程度是 5,只有一个认为是 4,那我肯定相信这两个了,投票多的就认为是它。或者取平均值,但我认为第一个算法更好,累计一个看法的输出,给它更大的权重。
第二种集成学习的方式就是堆叠。假设有两种推荐算法,我把第一种算法的输出的结果作为第二种算法的输入或者输入的一部分,再训练第二种算法。
第三种就是提升,我把一个推荐算法的输出值和我想要的真实的值的偏差再作为我的训练数据进行推理、进行训练,这也是一种集成学习的方法。
如何评估推荐系统
然后我想给大家谈一下,怎么评估推荐系统。
说到推荐系统的评估的方式,马上能想到 离线评估。根据有历史数据,一个用户喜不喜欢某个东西,我把历史数据分成两部分,一部分作为训练数据,一部分作为测试数据,我用训练数据的值来预测测试数据集里面的值,如果推荐的值跟我测试数据里面真实值相差少,就认为我是对的,这是很常见的一个方法,叫离线评估的方法。
第二个是 问卷调查,就是在网站或者页面上放置一个按纽,直接告诉用户:我现在给你推荐这个电影,你觉得好或者不好?用户就直接给做评价。或者是搞个问卷调查,问用户愿不愿意做个问卷调查。在设计问卷调查的时候要注意一下:同一个问题的两种形式,比如说问用户喜不喜欢《夏洛特烦恼》这个电影,可以首先用一个句子问:《夏洛特烦恼》是不是你喜欢的电影;第二个问题是:你是不是特别讨厌《夏洛特烦恼》这个电影,因为有这样两个加起来可以让用户重新思考,并且防止他有的时候只是点错了。还有就是所言非所意,这是什么意思?其实人有情感有理智,也有一些潜意识,他在问卷里告诉你他喜欢某个东西,不一定是他真的喜欢,这也是值得注意的一个问题。
第三个评估推荐系统方法是 用户学习。请一堆用户,做一个小规模的测试,他测试的不只是推荐系统好不好,还包括这个推荐系统最后呈现的用户界面好不好。这是针对整个用户体验进行测试,只是几十个用户小范围的测试,可能会发现系统 90% 左右的大问题,这是一个非常好的评估推荐系统的方法。
然后就是最近非常流行的所谓 A/B 测试,或者所谓 在线测试。一个新的模型出来,一个新的算法出来了,随机选择一些用户,比如 10% 的用户,用新算法的结果,另外 90% 还是用原来的算法的结果,然后比较新算法的 10% 的用户最后是不是获得了更好的推荐效果,比如说有购买更多的商品,或者是更踊跃的来访问我们的网站。
推荐系统架构 & 总结
接下来,我想总结一下。
有一个理论叫做:No free lunch theory,天下没有免费午餐。就是说 世界上没有一种算法在解决任何问题的情况下都比另外一种算法好,即使是现在最火热的深度学习算法,也并不意味着它会比传统的学习算法在解决任何问题下都好。所以组合多种不同的算法,就显得很重要,就是我前面提到的集成学习的方法。
Netflix 是美国的一个电影网站,相当于爱奇艺这种收费的电影网站,它的推荐系统非常有名,他们之前搞了个比赛,奖金有一百万美金,让大家比赛谁能够比他们原来的推荐算法提高 10% 的效果。最后赢得这个比赛的是当时 AT&T 的一个团队,他们用了几十种算法,把这几十种算法结合起来,做一个推荐系统,提高了 10.09% 的效果。这就是大家要注意的,把多种算法合在一起。
最后呢,我想谈的就是在架构,我以 Netflix 为架构为主说如果要做一个推荐系统,应该怎么来选择软件系统。
分别要把你的系统分成:离线的部分,近实时的部分和在线的部分。
离线的部分可以使用 Hadoop,Hive、Pig 或者 Spark 这种方式来做大规模的计算,因为这种计算都需要很长的时间。近实施的系统呢,他们使用 Cassandra 这种分布式数据库,MySQL,还有 Catch。还有实时系统,就是在内存里面计算这个系统,在这个部分的系统要求是:数据量比较少,算法比较简单,反馈一般都是毫秒为单位,在这个在实时系统里边一般都只做排序,在离线这部分可能要做比较复杂的事。
那这就是我今天要讲的所有内容,因为今天时间有限,我只能点到为止,如果你对推荐系统感兴趣,对我前面讲到的那些推荐系统想要有个更深入的了解,从算法到实现,都感兴趣的话,你可以扫我们贪心科技的二维码,进入我们的公众号,我们会在里面提交更多的内容。
weixin.qq.com/r/eCqPl5XE6… (二维码自动识别)
问答环节
Q1. 深度学习用户 ID 加 embedding 怎么操作?
A:Embeding 的本质是对输入的特征进行固定长度的编码。 用户 ID 的值可能是从 0 到 10000, 是一个整数, 通过 Embeding 层, 输出变为一个预先设定长度的向量。 这样做的目的是为了通过训练数据得到更丰富的信息, 这个向量能包含了对应用户 ID 的信息。
Q2. 探索和利用 和协同过滤 区别
A:探索和利用这种算法比较适合物品种类比较少的情况, 通常使用在推荐系统的最后一个阶段。 就是使用其它算法找出最有可能被某个类别用户接受的物品以后, 再使用探索和利用来对物品重新排序。协同过滤相对计算量小,更适合大规模数据的情况。
Q3:PPT 能共享吗?
A:请关注我们公众号,我们会在里面分享。
Q4. 能具体说一下集成学习中的堆叠和 boosting 吗?
A:堆叠:前一个算法的输出作为下一个算法的输入,或者输入的一部分Boosting:请一个算法的输出和实际值的差,作为本算法或者其他算法的输入
Q5:在线排序的算法现在主要应用比较广泛的都有哪些?
A:我不太明白你的具体问题。我假设你的问题是“Learning to rank”里面最流行的算法, 我的答案是:LambdaMART
Q6:请问用 spark 做推荐系统,除了 mllib 的 ALS 算法,还有什么实现方法呢?
A:Spark 官方只提供了协同过滤的 ALS 算法。 其他算法还需要自己实现。
Q7: 深度学习的输入层请详细讲解下?
A:这个问题太宽泛,需要具体情况具体分析。
Q8:item2item 协同过滤 跟矩阵分解 应用环境分别是什么样的?
A:item2item 的协同过滤算是一种最近邻方法 (Neighborhood Method), 相对矩阵分解, 比较容易实现, 比较容易微调, 可解释性也比较好。
Q9: 推荐算法通常都和用户画像一起使用吗?
A:如果你能够获取用户画像,当然应该利用。高质量的用户画像一定会提高推荐的效果。
Q10: 老师我想问下关于 LFM,在矩阵分解后再相乘,和目标矩阵做差的过程中,目标矩阵中没有过的值是怎么补了?
A:目标中没有的值不用补,做差的过程只需要考虑存在的值。
Q11:embedding 简单用 one hot?
A:理论上讲, 你可以直接使用全连接层和 one hot 编码代替 Embedding 层。 但是在许多情况下, 直接使用 one hot 编码作为输入计算量会大增。 例如在自然语言处理里面, 输入的 ID 值可能在百万级别, 如果直接 one hot 编码, 输入的向量就是百万级别的长度, 如果还需要使用 batching(批处理)来提高运输效率,那么内容占用和计算量都是巨大的。
Q12: 推荐系统有在工业(电力、化工、制造)领域的应用么?
A:我还没有发现推荐系统在电力,化工和制造业的应用。我想在工业 4.0, 先进制造业, 私人订制的领域,推荐系统应该是大有可为的。
Q13:刚才其实整个的这个课程讲了很多的算法,从协同过滤到深度学习,比如说一个工程师面对一个推荐系统的这样一个问题,大概有没有一个 guideline,对这类问题,我们需要采用这种一个协同过滤的方式,然后可能对另一个没问题可能采用深度学习的方式,有没有大概这样一个 guideline?
A:我的建议是先从基于内容的开始,基于内容的推荐系统和基于协同过滤的推荐系统开始,为什么呢?即使你用深度,即使你开始上更 fancy 的算法,你也不知道你的算法是不是比传统的算法好,如果你用一个转动的算法先做出来了,你再用更先进的算法,这至少让你有一个比较说这个算法好,不然的话,你都云里雾里,你即使用了更先进的算法,你不知道先进的算法是不是真的好,这是其一;
其二是越先进的算法越难以实现,比如说我讲到 Netflix 花一了一百万美金,得到了 AT&T 贝尔实验室得冠军的算法,但实际上他们并没有在他们的系统里面使用,为什么?因为太复杂了,一个算法在学术界里面可以很复杂,在工业界里面实现,要考虑到内存,考虑到计算量,考虑到一个程序员能不能看懂那个算法,考虑到你的代码是不是比较容易 maintain,那考虑到这些以后,Netflix 最后没有使用那个算法,也就是说,如果要着手的话,我建议你从前面的算法开始,最先使用的是基于内容的推荐和基于协同过滤的推荐,接下来才是更先进的算法。
Q14:还有一个问题:因为深度学习这种技术在图像识别这种领域已经很成熟了,但是我想了解一下比如说在工业界里面深度学习目前的在推荐系统这块应用情况到底是怎么样的?
A:现在深度学习很火了,那现在是不是有向深度学习做推荐系统的这样一个趋势呢?是有的,为什么有呢?比如说有的图片分享网站,或者像 YouTube 这种视频分享网站,大家往上面发东西,并没有人告诉你里面的内容是什么样,上传短片上去,这个系统它并不知道这个短片作者是谁,风格是什么,有哪些演员在里面,那什么都不知道,怎么知道这里面的相关性呢?
图片也一样,怎么知道推荐什么图片呢?深度学习,比如说 CNN 卷积神经网络,它可以做图像和视频里面的物质的识别、提取,他可以告诉你这个图片是奥巴马,这个图片是特朗普或者是其他人。包括音乐他会告诉你这个音乐的风格是什么。
所以说现在的确是有向深度学习进展的一个趋势,而且像 LSTM、RNN 它可以获取时间信息,就是时间上的相关性。比如说一个人他喜欢看《甄鬟传》,还喜欢看《纸牌屋》,但是他更喜欢看《纸牌屋》,那传统的推荐系统,我在看甄鬟传的 21 集,看完了我推荐什么呢?推荐《纸牌屋》,为什么?因为它更喜欢纸牌屋,但是在这个前提下,我告诉你:我正在看《甄鬟传》的 21 集,你是应该推荐我《纸牌屋》吗?你应该推荐我《甄鬟传》的 22 集,因为我正在看《甄鬟传》的 21 集。这种时间上的,时间序列上的这种预测,显然是用这种 LSTM、递归神经网络会比较好。
讲师介绍
袁源,英文名:Jerry,美国微软总部资深工程师、主导多款核心推荐系统的研发,是人工智能、分布式系统、云计算方面的专家。博士毕业于美国新泽西理工,拥有 14 年人工智能、推荐系统、自然语言处理、数字图像和视频处理项目经验。曾师从中国科学院王守觉院士从事人脸识别研究、共同发表论文。在美国博士期间,主要研究 NASA(美国航天局)支持的基于人工智能的空间天气预测项目。
更多干货内容,可关注AI前线,ID:ai-front,后台回复「AI」、「TF」、「大数据」可获得《AI前线》系列PDF迷你书和技能图谱。
作者:AI前线
链接:https://juejin.im/post/5a9a803ef265da2381551403
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
使用 Amazon Comprehend 检测客户评论的情绪
情绪分析是通过计算来确定一段文字蕴含的情绪是正面、负面、中立还是各种情绪交织在一起的一种流程。Amazon Comprehend 是由多个 API 组成的自然语言处理 (NLP) 文本分析服务,这些 API 可用于检测情绪 (以及关键短语、命名实体和语言),并根据一组文档执行主题建模。该服务利用先进的深度学习算法检测情绪,这些算法采用评分机制和属性来评估文本。Amazon Comprehend 训练数据集主要包括产品描述中的数据以及来自世界上最大的自然语言集合之一 – Amazon.com 上的客户评论。我们为您提供经过全方位训练的模型,该模型会根据新数据反复进行训练,确保与语言发展保持同步。目前大部分数据工程师和开发人员都不具备使用 ML 所需的一般技能。Amazon Comprehend 填补了这一技能空缺,可让开发人员利用现有的技能轻松使用 NLP。
本博文将向您介绍在事件驱动型无服务器架构 (使用 AWS 服务构建) 中,如何使用 Amazon Comprehend 来检测客户情绪。
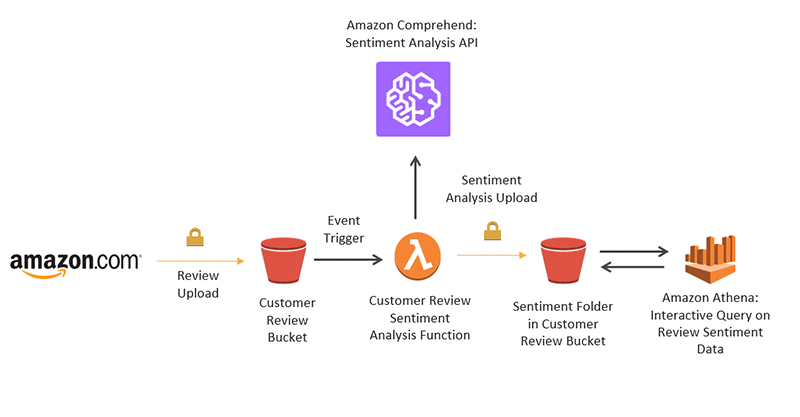
我们来看看 Amazon.com 上的产品评论,并使用 Amazon Comprehend 来对给定评论进行情绪分类。我们以 Amazon Echo、Amazon Echo Dot 和 Amazon Echo Show 的评论为例。我们将上传其他伪造的示例数据 (尽量不损害品牌声誉),然后使用具有细微差别的信息来模拟检索与产品有关的负面情绪,例如,正在召回的有缺陷、受损或危险商品。最后,我们使用 Amazon Athena 对负面评论进行交互查询并导出报告,以便让企业立即采取措施。
评论上传:用户将文本格式的客户评论上传到“Customer Review”(客户评论) 存储桶。
客户评论情绪分析函数:将安全上传评论作为触发评论情绪分析函数的 Amazon S3 事件,以便将评论下载到临时文件,然后调用 Amazon Comprehend 针对该评论执行文本分析,接着将总体情绪连同正面、负面、中立和混合信心评分一起输出到 CSV 文件。包含情绪的 CSV 文件将存储在同一“Customer Review”(客户评论) 存储桶内的“sentiment”(情绪) 文件夹中。
交互式 SQL 查询:使用 Amazon Athena 查询评论结果并重点关注负面情绪。
我们先部署 AWS CloudFormation 模板,以便预置与 Amazon S3、AWS Lambda 和 Amazon Comprehend API 进行交互所需的 AWS Identity and Access Management (IAM) 角色和 Lambda 函数。
| 区域 | 区域代码 | 启动 | |
| 1 | 美国东部 (弗吉尼亚北部) |
us-east-1 | |
注意:我们提供的 CloudFormation 模板使用 AWS Serverless Application Model (AWS SAM) 编写而成。AWS SAM 可以简化无服务器应用程序的函数、API 等的定义方式,还可以简化这些服务的某些功能 (例如,环境变量) 的定义方式。在 CloudFormation 模板中部署 SAM 模板时,需要执行转换步骤来将 SAM 模板转换为标准 CloudFormation,因此,您必须选择“创建更改集”按钮才能执行该转换。

部署完 IAM 角色、Lambda 函数和 S3 存储桶之后,请务必为您的 Comprehend 情绪分析函数创建 S3 事件触发器。

为了对使用案例进行说明,我们提取的是 Amazon Echo、Amazon Echo Dot 和 Amazon Echo Show 最上面的客户评论。我们将每条评论保存到文本文件中。
注意:Amazon 客户评论未经许可不得用于商业用途。在实施您的应用程序时,应当将此数据替换为您有权使用的数据源。




将每条评论上传到 S3 存储桶时,都会调用 Amazon Comprehend。由于 S3 上存储的评论数量不受限制,下一步就是要能够对这些评论进行查询,并找出对企业而言最重要的内容。在接下来的步骤中,我们将查询 S3 中现有的评论,然后过滤出负面评论。
我们将进一步深化此操作:按负面情绪从强到弱的顺序,使用 SQL 语句对所有评论进行排序。通过此查询,企业可以准确了解从何处着手并明智地安排周期。
在 Athena 控制台中,运行以下命令以在默认数据库中创建 Athena 表。 重要提示:请将 <bucket_name> 替换为之前创建的 S3 存储桶。
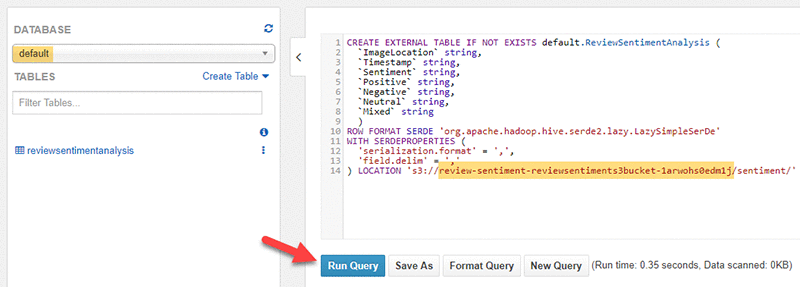
表成功创建后,请将以下 SQL 语句复制粘贴到编辑器中。 选择 Run Query (运行查询)。
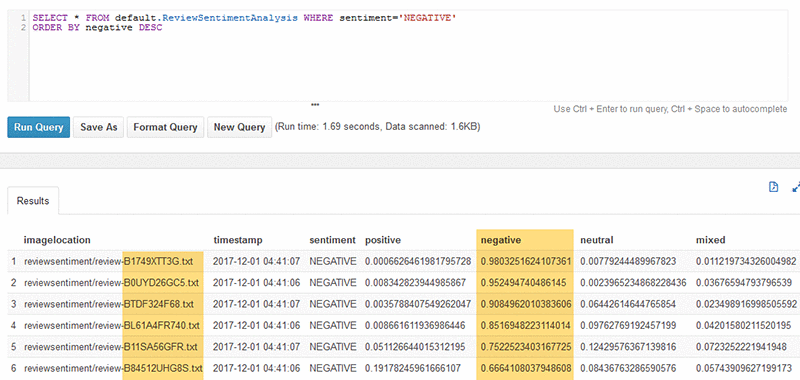
总而言之,Amazon Comprehend 可以快速识别发生变化的观点以及总体情绪,让您能够深入了解客户反馈,从而减少了解客户所需的时间和精力。此外,这也提供了一个立即采取相应措施的机会,以便满足客户不断变化的需求。
训练 NLP 不仅很困难,而且成本也非常昂贵。获取真实情绪的过程存在诸多障碍,例如,在对话不连贯、挖苦和讽刺时语言含义模糊不清,在使用表情符号的象征性表达中,仅捕获文本无法进行分析。所有这些障碍使得情绪更难以理解,因此,可能会影响所得到的结果的质量。 即使采用大型非结构化情绪富文本数据集和适当的分析方法,要想成功预测客户需求或对其作出反应,也需要做出大量的努力。这要求企业拥有相应的技能和专业知识来构建有效的机器学习 (ML) 模型,并在模型中包含可用来训练准确的情绪分类器的优化算法,然后运用 ML 技术来进一步降低系统不准确性,同时通过连续的反馈循环不断改进该模型。
Amazon Comprehend 将数据科学家需要执行的无差异繁重工作进行了抽象化,让您能够轻松将该服务集成到您的应用程序或分析解决方案中。此外,您还可以在 AWS 上一次查询几百万条评论,然后仅显示相关信息。可通过多种我们使用案例以外的方式来收集文字信息,例如,通过 Amazon Kinesis 或者 Amazon CloudWatch 中的计划事件实时提取数据。此外,提取并分析情绪之后,还可以洞察文本数据的其他很多方面。例如,您可以将数据的新字符串加载到数据仓库 (例如,Amazon Redshift) 中,在 Amazon QuickSight 等商业智能 (BI) 工具中查看该数据,或者将负面情绪评论复制到某个 S3 存储桶,以便触发我们的 Simple Notification Service (SNS) 以通知您的客户服务团队。
所有这些操作均在无服务器架构中执行,因此无需服务器即可编写和运行代码。归根结底,业务逻辑应该是您需要编写的唯一代码。我们将一如既往地继续以真正敏捷的方式对我们的模型进行迭代。请继续为我们提供反馈。现在充分发挥您的想象力,在 AWS 上尽情构建吧!
了解如何使用包括 Amazom Comprehend 和 Amazon Quicksight 在内的 Amazon ML 服务构建社交媒体控制面板。
 Todd Escalona 是一名解决方案架构师,他致力于向企业客户以及在初创社区中推广 AWS 云,同时通过聆听客户心声来了解客户目标,并以此为出发点来进行反向营销。他会确定需求,围绕具体使用案例提供架构指导,并且协助他人设计可扩展、可靠且性能高的应用程序和服务。他对各种各样的技术感兴趣,例如,人工智能、机器学习以及事件驱动型无服务器架构。
Todd Escalona 是一名解决方案架构师,他致力于向企业客户以及在初创社区中推广 AWS 云,同时通过聆听客户心声来了解客户目标,并以此为出发点来进行反向营销。他会确定需求,围绕具体使用案例提供架构指导,并且协助他人设计可扩展、可靠且性能高的应用程序和服务。他对各种各样的技术感兴趣,例如,人工智能、机器学习以及事件驱动型无服务器架构。